The Many Factors of Non-determinism of AI Assistants
Explore the various elements that contribute to the non-deterministic behavior of AI assistants and its impact.
AI assistants like ChatGPT, Gemini, Claude, DeepSeek, and Kimi share one key characteristic: their answers are non-deterministic. Even with the same assistant and the same query, the answer can be different every time. This post will walk you through the many factors contributing to this variance.
The diagram below outlines four layers contributing to this non-determinism. We’ll talk about LLM first, then compute infra, followed by the AI assistant systems and finally user behavior and interactions with AI systems.
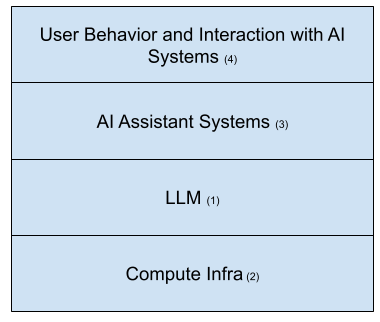
Large Language Model (LLM)
The core of AI assistants are Large Language Models (LLMs), which are fundamentally statistical models good at predicting the next token. Given the preceding context—including the system prompt and the user's query—they generate tokens sequentially to form the final answer.
These models use a dictionary of tokens, which are often word fragments (for simplicity, we will refer to them as words for the rest of this post). Each time, the model infers the probability of each word in the dictionary being the “correct” next word. For example, given "a cat is sitting on a _.", the word "sofa" might have a probability of 0.4, "stool" 0.2, "banana" 0.000001, and so on.
During answer generation, a model can be configured to select the next predicted word based on various strategies. Greedy decoding, for example, always selects the word with the highest probability. LLM APIs expose several parameters, such as top-p, top-K, and temperature, to control the randomness of next-word selection.
Introducing randomness allows for more creativity and diversity in the output and it’s useful in some domains. While the exact configuration of these parameters by AI assistants is proprietary, it is likely they are not using pure greedy decoding, meaning some inherent randomness exists in the model's response generation.
What if we set the temperature to 0 to minimize randomness? Even then, the response turns out to be non-deterministic.
Compute Infra
LLM parameters are represented as high-dimensional floating-point vectors. During response generation, a large number of floating-point operations are executed in a highly parallel and performant manner to produce the final probability predictions.
Floating Point Non-associativity
However, because floating-point numbers cannot be represented precisely in computers, they are subject to floating-point non-associativity. Basically,
As an example, suppose we have the following:
When are done first, the smaller number is lost as the floating point data type is unable to represent the large number at such precision.
Batch Variant
Floating-point non-associativity alone does not produce non-determinism; as long as the summation order is deterministic, the result for each run will be the same. However, the summation order in certain operations, including matrix multiplication, is impacted by the batch size, which in turn is affected by service load [1].
When server load changes (due to varying user request volume), the batch size changes. When the batch size changes, the compute infrastructure adopts different parallelism strategies to speed up operations, resulting in a different summation order and thus producing different results.
Researchers have proven it is possible to mitigate this non-determinism. However, these techniques currently incur a performance cost and are not widely adopted.
AI Assistant Systems: Tool Use and Agentic Loop
Most AI assistants use tools (e.g., web search, code interpreters) to enhance their capabilities and produce better results. Beyond the tools visible to end users, AI assistants are sophisticated internal systems consisting of one or more LLMs, internal tools, and services. These tools may be used to store, retrieve, augment, or filter information flowing into and out of the LLMs. For example, additional copyright checkers could be applied to filter out responses that are simply reciting copyrighted paragraphs.
These systems often run in an agentic loop, which repeatedly makes LLM calls to plan, invoke tools, process tool responses, and iterate until a final answer is produced.
Since each LLM call is non-deterministic, the non-determinism can compound during an agentic run. For example, a complicated query might trigger several web searches. The LLM reads and assembles these responses to produce an answer. The number of searches, which specific search results are read, and the order in which the content is fed to the LLM can all vary across different runs, producing different results. Below is an example query to Claude. The same query resulted in a different number of web searches.

User Behavior and Interaction with AI Systems
Multi Turn Conversations
The interaction model for AI assistants is mostly conversational, leading to multi-turn conversations. The answer is heavily dependent on the context established in the previous turns of the same session.
Memory and Personalization
Major AI assistants [2][3][4] can memorize past conversations and build knowledge about users as they converse. This knowledge, along with contextual information (like language settings, location, device, and time), is used to personalize the answers to be more relevant and contextual.
While search also features personalization (primarily in the ranking of results), AI assistants process large chunks of information in both input and output, meaning the output variance can be significantly greater.
Impact of Non Determinism
While AI assistants produce non deterministic results each time, as an end user, the results are mostly sensible and useful. For most queries, there is no single correct answer, but a universe of useful responses. Even for questions with a single correct answer, such as math problems, the natural language expression can still vary. The LLM model training process and the AI assistants systems are designed to work well under these situations. There are, however, domains where reproducibility and determinism are highly desirable (e.g., medicine, aerospace engineering), often requiring specialized models and system engineering to ensure reliable operation.
References
- He, Horace and Thinking Machines Lab, "Defeating Nondeterminism in LLM Inference", Thinking Machines Lab: Connectionism, Sep 2025.
- Memory and new controls for ChatGPT. https://openai.com/index/memory-and-new-controls-for-chatgpt/
- Bringing memory to teams at work. https://www.anthropic.com/news/memory
- Personalized help from Gemini. https://gemini.google/overview/personalization/